
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
rlpyt: A Research Code Base for Deep Reinforcement Learning in PyTorch
Since the recent advent of deep reinforcement learning for game play and simulated robotic control, a multitude of new algorithms have flourished. Most are model-free algorithms which can be categorized into three families: deep Q-learning, policy gradients, and Q-value policy gradients. These have developed along separate lines of research, such that few, if any, code bases incorporate all three kinds. Yet these algorithms share a great depth of common deep reinforcement learning machinery. We are pleased to share rlpyt, which implements all three algorithm families on top of a shared, optimized infrastructure, in a single repository. It contains modular implementations of many common deep RL algorithms in Python using PyTorch, a leading deep learning library. rlpyt is designed as a high-throughput code base for small- to medium-scale research in deep RL. This paper summarizes its features, algorithms implemented, and relation to prior work, and concludes with detailed implementation and usage notes. rlpyt can be found on GitHub.
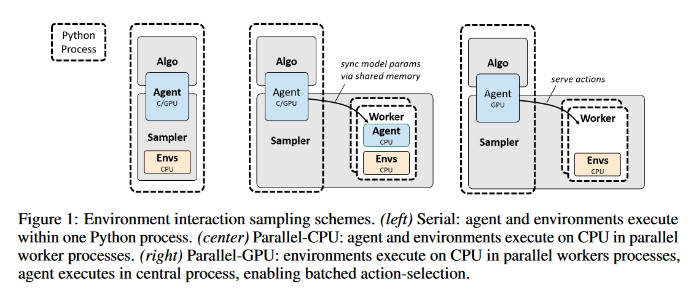
SoftTriple Loss: Deep Metric Learning Without Triplet Sampling
Distance metric learning (DML) is to learn the embeddings where examples from the same class are closer than examples from different classes. It can be cast as an optimization problem with triplet constraints. Due to the vast number of triplet constraints, a sampling strategy is essential for DML. With the tremendous success of deep learning in classifications, it has been applied for DML. When learning embeddings with deep neural networks (DNNs), only a mini-batch of data is available at each iteration. The set of triplet constraints has to be sampled within the mini-batch. Since a mini-batch cannot capture the neighbors in the original set well, it makes the learned embeddings sub-optimal. On the contrary, optimizing SoftMax loss, which is a classification loss, with DNN shows a superior performance in certain DML tasks. This paper investigates the formulation of SoftMax. The analysis shows that SoftMax loss is equivalent to a smoothed triplet loss where each class has a single center. In real-world data, one class can contain several local clusters rather than a single one, e.g., birds of different poses. Therefore, this paper proposes the SoftTriple loss to extend the SoftMax loss with multiple centers for each class.
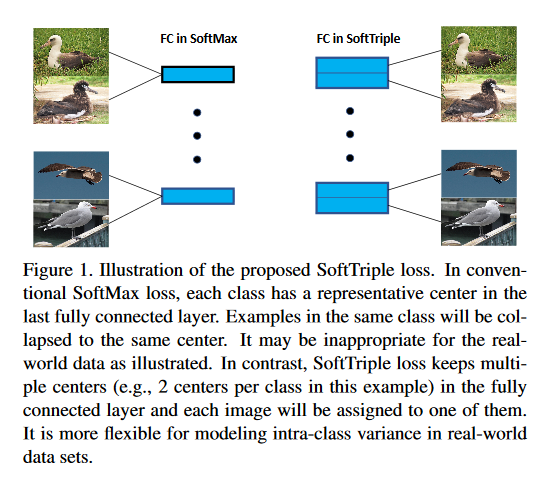
Distributed Machine Learning on Mobile Devices: A Survey

In recent years, mobile devices have gained increasingly development with stronger computation capability and larger storage. Some of the computation-intensive machine learning and deep learning tasks can now be run on mobile devices. To take advantage of the resources available on mobile devices and preserve users’ privacy, the idea of mobile distributed machine learning is proposed. It uses local hardware resources and local data to solve machine learning sub-problems on mobile devices, and only uploads computation results instead of original data to contribute to the optimization of the global model. This architecture can not only relieve computation and storage burden on servers, but also protect the users’ sensitive information. Another benefit is the bandwidth reduction, as various kinds of local data can now participate in the training process without being uploaded to the server. This paper provides a comprehensive survey on recent studies of mobile distributed machine learning and surveys a number of widely-used mobile distributed machine learning methods.
Espresso: A Fast End-to-end Neural Speech Recognition Toolkit
This paper presents Espresso, an open-source, modular, extensible end-to-end neural automatic speech recognition (ASR) toolkit based on the deep learning library PyTorch and the popular neural machine translation toolkit fairseq. Espresso supports distributed training across GPUs and computing nodes, and features various decoding approaches commonly employed in ASR, including look-ahead word-based language model fusion, for which a fast, parallelized decoder is implemented. Espresso achieves state-of-the-art ASR performance on the WSJ, LibriSpeech, and Switchboard data sets among other end-to-end systems without data augmentation, and is 4–11x faster for decoding than similar systems (e.g. ESPnet). Espresso can be found on GitHub.
MUSICNN: Pre-trained Convolutional Neural Networks for Music Audio Tagging
Pronounced as “musician”, the musicnn library contains a set of pre-trained musically motivated convolutional neural networks for music audio tagging. The repository also includes some pre-trained vgg-like baselines. These models can be used as out-of-the-box music audio taggers, as music feature extractors, or as pre-trained models for transfer learning. musiccn can be found on GitHub.

DeepPrivacy: A Generative Adversarial Network for Face Anonymization
This paper proposes a novel architecture which is able to automatically anonymize faces in images while retaining the original data distribution. We ensure total anonymization of all faces in an image by generating images exclusively on privacy-safe information. The model is based on a conditional generative adversarial network, generating images considering the original pose and image background. The conditional information enables the method to generate highly realistic faces with a seamless transition between the generated face and the existing background. DeepPrivacy can be found on GitHub.

Sign up for the free insideBIGDATA newsletter.



Speak Your Mind