
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of learning methods you may use one day in the solution of data science problems. We hope to save you some time by picking out articles that represent the most promise for the typical data scientist. The articles listed below represent a fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
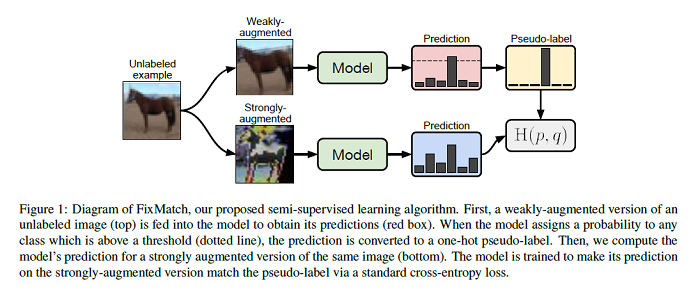
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
Semi-supervised learning (SSL) provides an effective means of leveraging unlabeled data to improve a model’s performance. This paper from Google Research demonstrates the power of a simple combination of two common SSL methods: consistency regularization and pseudo-labeling. The new algorithm, FixMatch, first generates pseudo-labels using the model’s predictions on weakly-augmented unlabeled images. For a given image, the pseudo-label is only retained if the model produces a high-confidence prediction. The model is then trained to predict the pseudo-label when fed a strongly-augmented version of the same image. Despite its simplicity, it’s shown that FixMatch achieves state-of-the-art performance across a variety of standard semi-supervised learning benchmarks, including 94.93% accuracy on CIFAR-10 with 250 labels and 88.61% accuracy with 40 — just 4 labels per class. The code for this paper is available HERE.
Markov Chain Monte Carlo Methods, a survey with some frequent misunderstandings
This paper reviews some of the most standard MCMC tools used in Bayesian computation, along with vignettes on standard misunderstandings of these approaches.

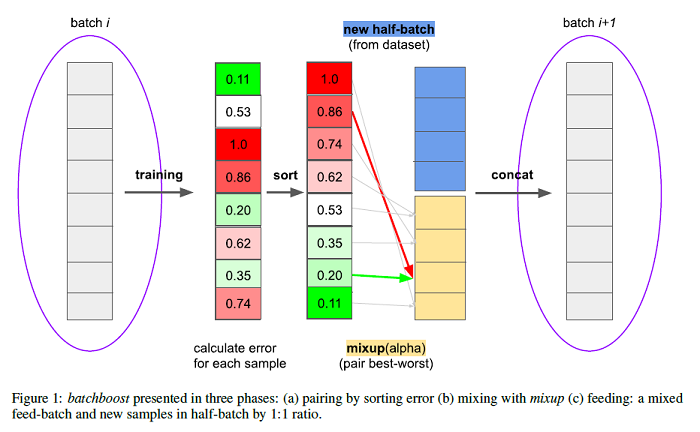
batchboost: regularization for stabilizing training with resistance to underfitting & overfitting

Overfitting & underfitting and stable training are an important challenges in machine learning. Current approaches for these issues are mixup, SamplePairing and BC learning. This paper states the hypothesis that mixing many images together can be more effective than just two. Batchboost pipeline has three stages: (a) pairing: method of selecting two samples. (b) mixing: how to create a new one from two samples. (c) feeding: combining mixed samples with new ones from dataset into batch (with ratio γ). The batchboost method is slightly better than SamplePairing technique on small datasets (up to 5%). Batchboost provides stable training on not tuned parameters (like weight decay), thus its a good method to test performance of different architectures. The code for this paper is available HERE.
Advbox: a toolbox to generate adversarial examples that fool neural networks
In recent years, neural networks have been extensively deployed for computer vision tasks, particularly visual classification problems, where new algorithms reported to achieve or even surpass the human performance. Recent studies have shown that they are all vulnerable to the attack of adversarial examples. Small and often imperceptible perturbations to the input images are sufficient to fool the most powerful neural networks. Advbox is a toolbox to generate adversarial examples that fool neural networks in PaddlePaddle, PyTorch, Caffe2, MxNet, Keras, TensorFlow and it can benchmark the robustness of machine learning models. Compared to previous work, this platform supports black box attacks on Machine-Learning-as-a-service, as well as more attack scenarios, such as Face Recognition Attack, Stealth T-shirt, and Deepfake Face Detect. The code for this paper is available HERE.

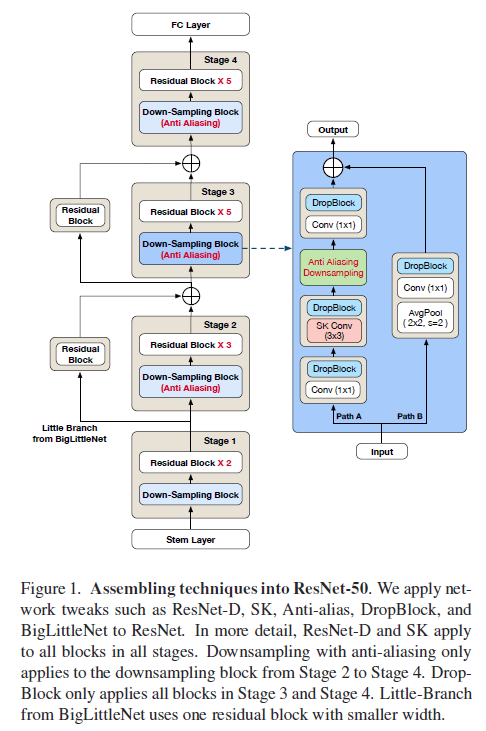
Compounding the Performance Improvements of Assembled Techniques in a Convolutional Neural Network
Recent studies in image classification have demonstrated a variety of techniques for improving the performance of Convolutional Neural Networks (CNNs). However, attempts to combine existing techniques to create a practical model are still uncommon. This paper carries out extensive experiments to validate that carefully assembling these techniques and applying them to a basic CNN model in combination can improve the accuracy and robustness of the model while minimizing the loss of throughput. For example, a proposed ResNet-50 shows an improvement in top-1 accuracy from 76.3% to 82.78%, and an mCE improvement from 76.0% to 48.9%, on the ImageNet ILSVRC2012 validation set. With these improvements, inference throughput only decreases from 536 to 312. The resulting model significantly outperforms state-of-the-art models with similar accuracy in terms of mCE and inference throughput. To verify the performance improvement in transfer learning, fine grained classification and image retrieval tasks were tested on several open datasets and showed that the improvement to backbone network performance boosted transfer learning performance significantly. The code for this paper is available HERE.
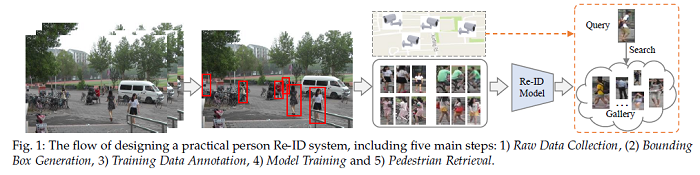
Deep Learning for Person Re-identification: A Survey and Outlook
Person re-identification (Re-ID) aims at retrieving a person of interest across multiple non-overlapping cameras. With the advancement of deep neural networks and increasing demand of intelligent video surveillance, it has gained significantly increased interest in the computer vision community. By dissecting the involved components in developing a person Re-ID system, it is possible to categorize it into the closed-world and open-world settings. The widely studied closed-world setting is usually applied under various research-oriented assumptions, and has achieved inspiring success using deep learning techniques on a number of data sets. This paper first conducts a comprehensive overview with in-depth analysis for closed-world person Re-ID from three different perspectives, including deep feature representation learning, deep metric learning and ranking optimization. With the performance saturation under closed-world setting, the research focus for person Re-ID has recently shifted to the open-world setting, facing more challenging issues. This setting is closer to practical applications under specific scenarios. The paper summarizes the open-world Re-ID in terms of five different aspects. By analyzing the advantages of existing methods, the paper designs a powerful AGW baseline, achieving state-of-the-art or at least comparable performance on both single- and cross-modality Re-ID tasks. Meanwhile, the paper introduces a new evaluation metric (mINP) for person Re-ID, indicating the cost for finding all the correct matches, which provides an additional criteria to evaluate the Re-ID system for real applications. The code for this paper is available HERE.
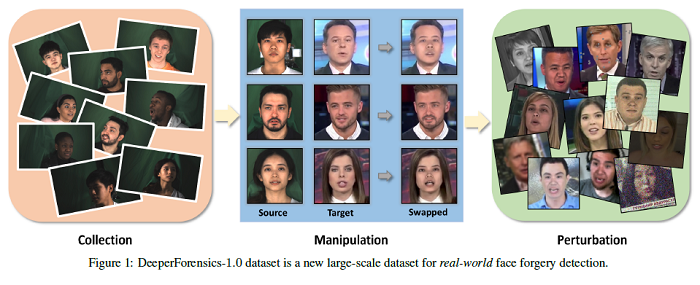
DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection
This paper presents an on-going effort of constructing a large-scale benchmark, DeeperForensics-1.0, for face forgery detection. The benchmark represents the largest face forgery detection data set by far, with 60, 000 videos constituted by a total of 17.6 million frames, 10 times larger than existing data sets of the same kind. Extensive real-world perturbations are applied to obtain a more challenging benchmark of larger scale and higher diversity. All source videos in DeeperForensics-1.0 are carefully collected, and fake videos are generated by a newly proposed end-to-end face swapping framework. The quality of generated videos outperforms those in existing datasets, validated by user studies. The benchmark features a hidden test set, which contains manipulated videos achieving high deceptive scores in human evaluations. The code for this paper is available HERE.
Sign up for the free insideBIGDATA newsletter.



Speak Your Mind