
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
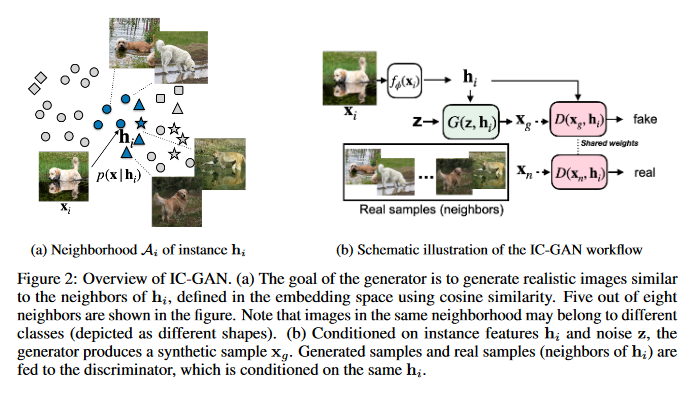
Generative Adversarial Networks (GANs) can generate near photo realistic images in narrow domains such as human faces. Yet, modeling complex distributions of datasets such as ImageNet and COCO-Stuff remains challenging in unconditional settings. This paper takes inspiration from kernel density estimation techniques and introduces a non-parametric approach to modeling distributions of complex datasets. The data manifold is partitioned into a mixture of overlapping neighborhoods described by a datapoint and its nearest neighbors, and a model is introduced called instance-conditioned GAN (IC-GAN), which learns the distribution around each datapoint. Experimental results on ImageNet and COCO-Stuff show that IC-GAN significantly improves over unconditional models and unsupervised data partitioning baselines. It’s also shown that IC-GAN can effortlessly transfer to datasets not seen during training by simply changing the conditioning instances, and still generate realistic images. The GitHub repo associated with this paper can be found HERE.
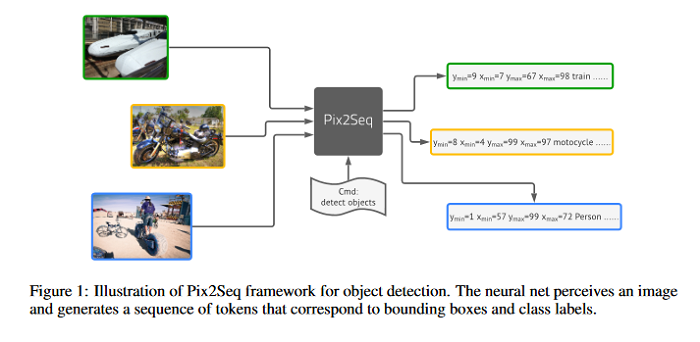
Pix2seq: A Language Modeling Framework for Object Detection
This paper presents Pix2Seq, a simple and generic framework for object detection. Unlike existing approaches that explicitly integrate prior knowledge about the task, Google researchers including Geoffrey Hinton, simply cast object detection as a language modeling task conditioned on the observed pixel inputs. Object descriptions (e.g., bounding boxes and class labels) are expressed as sequences of discrete tokens, and a neural net is trained to perceive the image and generate the desired sequence. The approach is based mainly on the intuition that if a neural net knows about where and what the objects are, we just need to teach it how to read them out. Beyond the use of task-specific data augmentations, the approach makes minimal assumptions about the task, yet it achieves competitive results on the challenging COCO dataset, compared to highly specialized and well optimized detection algorithms. The GitHub repo associated with this paper can be found HERE.
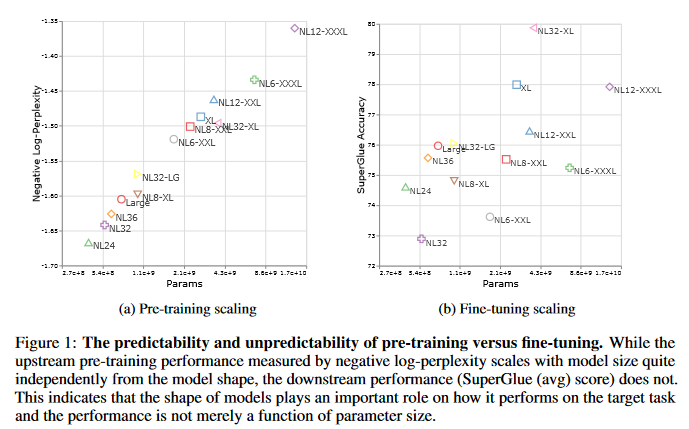
Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers
There remain many open questions pertaining to the scaling behavior of Transformer architectures. These scaling decisions and findings can be critical, as training runs often come with an associated computational cost which have both financial and/or environmental impact. The goal of this paper is to present scaling insights from pretraining and finetuning Transformers. While Kaplan et al. presents a comprehensive study of the scaling behavior of Transformer language models, the scope is only on the upstream (pretraining) loss. Therefore, it is still unclear if these set of findings transfer to downstream task within the context of the pretrain-finetune paradigm. The key findings of this paper are as follows: (1) aside from only the model size, model shape matters for downstream fine-tuning, (2) scaling protocols operate differently at different compute regions, (3) widely adopted T5-base and T5-large sizes are Pareto-inefficient. To this end, improved scaling protocols are presented whereby the redesigned models achieve similar downstream fine-tuning quality while having 50\% fewer parameters and training 40\% faster compared to the widely adopted T5-base model.
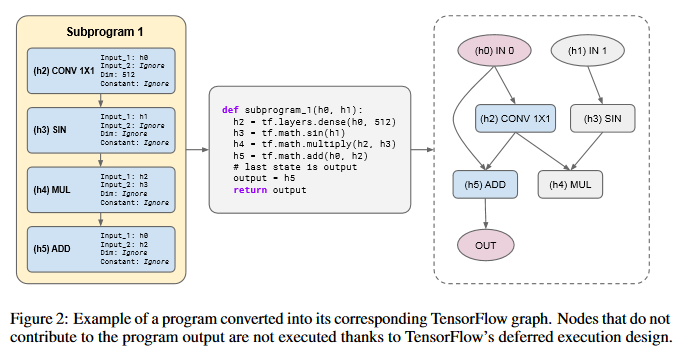
Primer: Searching for Efficient Transformers for Language Modeling

Large Transformer models have been central to recent advances in natural language processing. The training and inference costs of these models, however, have grown rapidly and become prohibitively expensive. The paper aims to reduce the costs of Transformers by searching for a more efficient variant. Compared to previous approaches, the search is performed at a lower level, over the primitives that define a Transformer TensorFlow program. An architecture is identified, named Primer, that has a smaller training cost than the original Transformer and other variants for auto-regressive language modeling. Primer’s improvements can be mostly attributed to two simple modifications: squaring ReLU activations and adding a depthwise convolution layer after each Q, K, and V projection in self-attention. The GitHub repo associated with this paper can be found HERE.
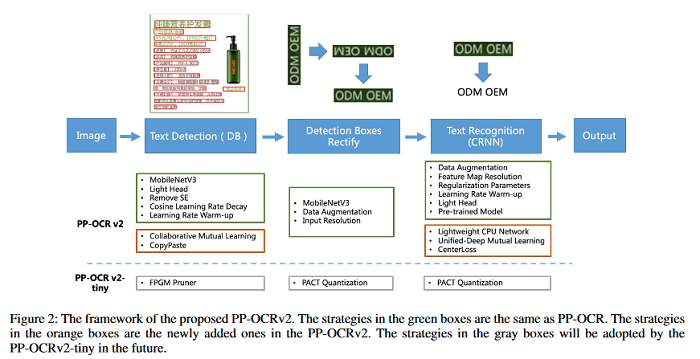
PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System
Optical Character Recognition (OCR) systems have been widely used in various of application scenarios. Designing an OCR system is still a challenging task. This paper proposes a robust OCR system, i.e. PP-OCRv2. A bag of tricks is introduced to train a better text detector and a better text recognizer, which include Collaborative Mutual Learning (CML), CopyPaste, Lightweight CPUNetwork (LCNet), Unified-Deep Mutual Learning (U-DML) and Enhanced CTCLoss. Experiments on real data show that the precision of PP-OCRv2 is 7% higher than PP-OCR under the same inference cost. It is also comparable to the server models of the PP-OCR which uses ResNet series as backbones. All of the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleOCR which is powered by PaddlePaddle. The GitHub report associated with this paper can be found HERE.
Visual Anomaly Detection for Images: A Survey
Visual anomaly detection is an important and challenging problem in the field of machine learning and computer vision. This problem has attracted a considerable amount of attention in relevant research communities. Especially in recent years, the development of deep learning has sparked an increasing interest in the visual anomaly detection problem and brought a great variety of novel methods. This paper provides a comprehensive survey of the classical and deep learning-based approaches for visual anomaly detection in the literature. The relevant approaches are grouped in view of their underlying principles and discuss their assumptions, advantages, and disadvantages carefully. The aim is to help the researchers to understand the common principles of visual anomaly detection approaches and identify promising research directions in this field.
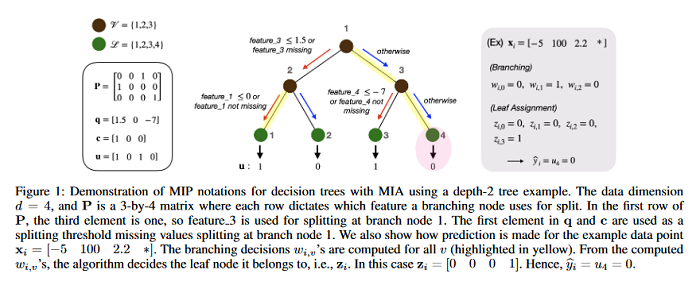
Fairness without Imputation: A Decision Tree Approach for Fair Prediction with Missing Values
This paper investigates the fairness concerns of training a machine learning model using data with missing values. Even though there are a number of fairness intervention methods in the literature, most of them require a complete training set as input. In practice, data can have missing values, and data missing patterns can depend on group attributes (e.g. gender or race). Simply applying off-the-shelf fair learning algorithms to an imputed dataset may lead to an unfair model. This paper theoretically analyzes different sources of discrimination risks when training with an imputed dataset. An integrated approach is proposed based on decision trees that does not require a separate process of imputation and learning. Instead, a tree is trained with missing incorporated as attribute (MIA), which does not require explicit imputation, and a fairness-regularized objective function is optimized. The approach outperforms existing fairness intervention methods applied to an imputed dataset, through several experiments on real-world datasets.
Merlion: A Machine Learning Library for Time Series
This paper introduces Merlion, an open-source machine learning library for time series. It features a unified interface for many commonly used models and datasets for anomaly detection and forecasting on both univariate and multivariate time series, along with standard pre/post-processing layers. It has several modules to improve ease-of-use, including visualization, anomaly score calibration to improve interpetability, AutoML for hyperparameter tuning and model selection, and model ensembling. Merlion also provides a unique evaluation framework that simulates the live deployment and re-training of a model in production. This library aims to provide engineers and researchers a one-stop solution to rapidly develop models for their specific time series needs and benchmark them across multiple time series datasets. This technical report highlights Merlion’s architecture and major functionalities, and a report of benchmark numbers across different baseline models and ensembles.

A Machine Learning Pipeline to Examine Political Bias with Congressional Speeches
Computational methods to model political bias in social media involve several challenges due to heterogeneity, high-dimensional, multiple modalities, and the scale of the data. Political bias in social media has been studied in multiple viewpoints like media bias, political ideology, echo chambers, and controversies using machine learning pipelines. Most of the current methods rely heavily on the manually-labeled ground-truth data for the underlying political bias prediction tasks. Limitations of such methods include human-intensive labeling, labels related to only a specific problem, and the inability to determine the near future bias state of a social media conversation. This paper addresses such problems and give machine learning approaches to study political bias in two ideologically diverse social media forums: Gab and Twitter without the availability of human-annotated data.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind