
In this recurring monthly feature, we filter recent research papers appearing on the arXiv.org preprint server for compelling subjects relating to AI, machine learning and deep learning – from disciplines including statistics, mathematics and computer science – and provide you with a useful “best of” list for the past month. Researchers from all over the world contribute to this repository as a prelude to the peer review process for publication in traditional journals. arXiv contains a veritable treasure trove of statistical learning methods you may use one day in the solution of data science problems. The articles listed below represent a small fraction of all articles appearing on the preprint server. They are listed in no particular order with a link to each paper along with a brief overview. Links to GitHub repos are provided when available. Especially relevant articles are marked with a “thumbs up” icon. Consider that these are academic research papers, typically geared toward graduate students, post docs, and seasoned professionals. They generally contain a high degree of mathematics so be prepared. Enjoy!
Explaining generalization in deep learning: progress and fundamental limits

This dissertation studies a fundamental open challenge in deep learning theory: why do deep networks generalize well even while being overparameterized, unregularized and fitting the training data to zero error? The first part of the thesis empirically studies how training deep networks via stochastic gradient descent implicitly controls the networks’ capacity. Subsequently, to show how this leads to better generalization, we will derive data-dependent uniform-convergence-based generalization bounds with improved dependencies on the parameter count.
Uniform convergence has in fact been the most widely used tool in deep learning literature, thanks to its simplicity and generality. Given its popularity, this thesis will also take a step back to identify the fundamental limits of uniform convergence as a tool to explain generalization. In particular, it is shown that in some example overparameterized settings, any uniform convergence bound will provide only a vacuous generalization bound.
With this realization in mind, the last part of the thesis will change course and introduce an empirical technique to estimate generalization using unlabeled data. The technique does not rely on any notion of uniform-convergece-based complexity and is remarkably precise.
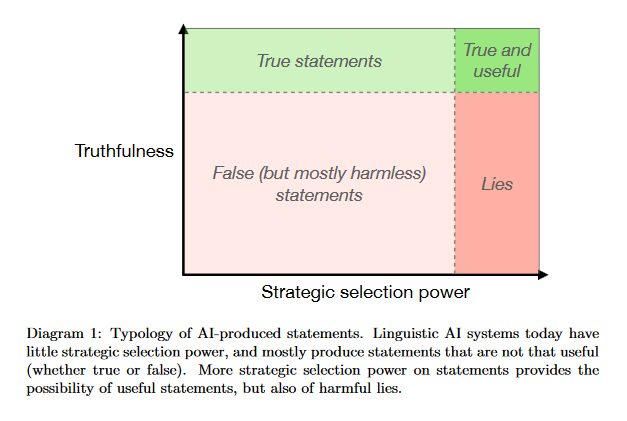
Truthful AI: Developing and governing AI that does not lie
In many contexts, lying — the use of verbal falsehoods to deceive — is harmful. While lying has traditionally been a human affair, AI systems that make sophisticated verbal statements are becoming increasingly prevalent. This raises the question of how we should limit the harm caused by AI “lies” (i.e. falsehoods that are actively selected for). Human truthfulness is governed by social norms and by laws (against defamation, perjury, and fraud). Differences between AI and humans present an opportunity to have more precise standards of truthfulness for AI, and to have these standards rise over time. This could provide significant benefits to public epistemics and the economy, and mitigate risks of worst-case AI futures. Establishing norms or laws of AI truthfulness will require significant work to: (1) identify clear truthfulness standards; (2) create institutions that can judge adherence to those standards; and (3) develop AI systems that are robustly truthful.
Hierarchical Transformers Are More Efficient Language Models
Transformer models yield impressive results on many NLP and sequence modeling tasks. Remarkably, Transformers can handle long sequences which allows them to produce long coherent outputs: full paragraphs produced by GPT-3 or well-structured images produced by DALL-E. These large language models are impressive but also very inefficient and costly, which limits their applications and accessibility. This paper postulates that having an explicit hierarchical architecture is the key to Transformers that efficiently handle long sequences. To verify this claim, the researchers first study different ways to downsample and upsample activations in Transformers so as to make them hierarchical. The best performing upsampling and downsampling layers are used to create Hourglass – a hierarchical Transformer language model. Hourglass improves upon the Transformer baseline given the same amount of computation and can yield the same results as Transformers more efficiently. In particular, Hourglass sets new state-of-the-art for Transformer models on the ImageNet32 generation task and improves language modeling efficiency on the widely studied enwik8 benchmark.

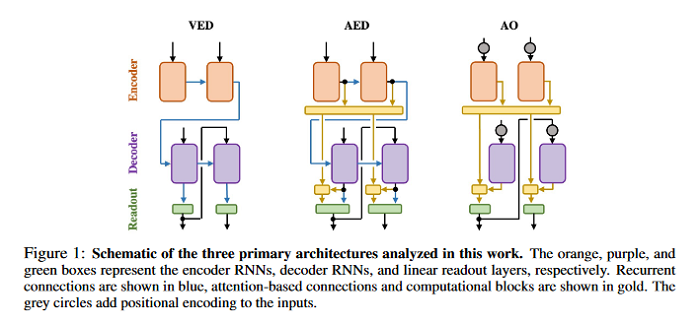
Understanding How Encoder-Decoder Architectures Attend
Encoder-decoder networks with attention have proven to be a powerful way to solve many sequence-to-sequence tasks. In these networks, attention aligns encoder and decoder states and is often used for visualizing network behavior. However, the mechanisms used by networks to generate appropriate attention matrices are still mysterious. Moreover, how these mechanisms vary depending on the particular architecture used for the encoder and decoder (recurrent, feed-forward, etc.) are also not well understood. This paper investigates how encoder-decoder networks solve different sequence-to-sequence tasks. Introduced is a way of decomposing hidden states over a sequence into temporal (independent of input) and input-driven (independent of sequence position) components. This reveals how attention matrices are formed: depending on the task requirements, networks rely more heavily on either the temporal or input-driven components. These findings hold across both recurrent and feed-forward architectures despite their differences in forming the temporal components. Overall, the results provide new insight into the inner workings of attention-based encoder-decoder networks.
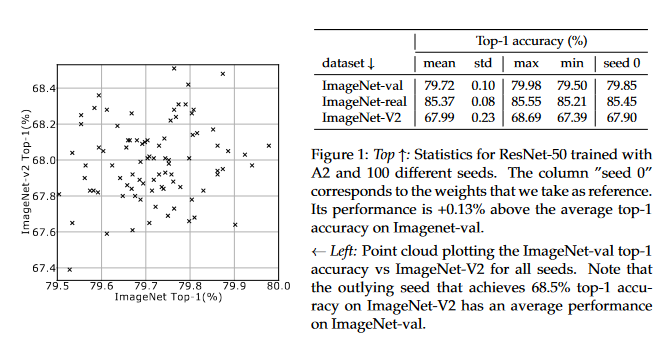
ResNet strikes back: An improved training procedure in timm
The influential Residual Networks designed by He et al. remain the gold-standard architecture in numerous scientific publications. They typically serve as the default architecture in studies, or as baselines when new architectures are proposed. Yet there has been significant progress on best practices for training neural networks since the inception of the ResNet architecture in 2015. Novel optimization & data-augmentation have increased the effectiveness of the training recipes. This paper re-evaluates the performance of the vanilla ResNet-50 when trained with a procedure that integrates such advances. Competitive training settings and pre-trained models in the timm open-source library are shared, with the hope that they will serve as better baselines for future work. For instance, with our more demanding training setting, a vanilla ResNet-50 reaches 80.4% top-1 accuracy at resolution 224×224 on ImageNet-val without extra data or distillation. The GitHub repo associated with this paper can be found HERE.
Yuan 1.0: Large-Scale Pre-trained Language Model in Zero-Shot and Few-Shot Learning
Recent work like GPT-3 has demonstrated excellent performance of Zero-Shot and Few-Shot learning on many natural language processing (NLP) tasks by scaling up model size, dataset size and the amount of computation. However, training a model like GPT-3 requires huge amount of computational resources which makes it challengeable to researchers. This paper proposes a method that incorporates large-scale distributed training performance into model architecture design. With this method, Yuan 1.0, the current largest singleton language model with 245B parameters, achieves excellent performance on thousands GPUs during training, and the state-of-the-art results on NLP tasks. A data processing method is designed to efficiently filter massive amount of raw data. The current largest high-quality Chinese corpus with 5TB high quality texts is built based on this method. In addition, a calibration and label expansion method is proposed to improve the Zero-Shot and Few-Shot performance, and steady improvement is observed on the accuracy of various tasks. Yuan 1.0 presents strong capacity of natural language generation, and the generated articles are difficult to distinguish from the human-written ones.
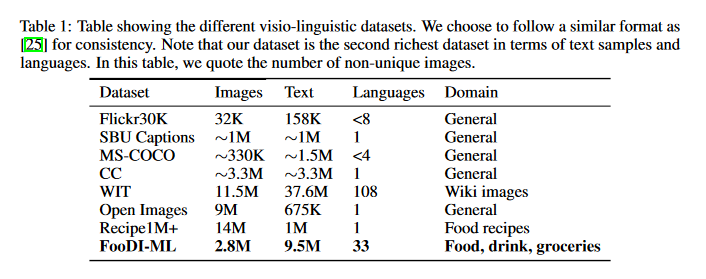
FooDI-ML – a large multi-language dataset of food, drinks and groceries images and descriptions
This paper introduces the Food Drinks and groceries Images Multi Lingual (FooDI-ML) dataset. This dataset contains over 1.5M unique images and over 9.5M store names, product names descriptions, and collection sections gathered from the Glovo application. The data made available corresponds to food, drinks and groceries products from 37 countries in Europe, the Middle East, Africa and Latin America. The dataset comprehends 33 languages, including 870K samples of languages of countries from Eastern Europe and Western Asia such as Ukrainian and Kazakh, which have been so far underrepresented in publicly available visio-linguistic datasets. The dataset also includes widely spoken languages such as Spanish and English. To assist further research, included is a benchmark over the text-image retrieval task using ADAPT, a SotA existing technique. The GitHub repo associated with this paper can be found HERE.
The Causal Loss: Driving Correlation to Imply Causation
Most algorithms in classical and contemporary machine learning focus on correlation-based dependence between features to drive performance. Although success has been observed in many relevant problems, these algorithms fail when the underlying causality is inconsistent with the assumed relations. This paper proposes a novel model-agnostic loss function called Causal Loss that improves the interventional quality of the prediction using an intervened neural-causal regularizer. In support of the theoretical results, the experimental illustration shows how causal loss bestows a non-causal associative model (like a standard neural net or decision tree) with interventional capabilities.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind