
How to take futile testing data and make it into its biggest asset for developer productivity.
The act of staging either in plays, real estate, or software development has been an industry practice for many decades. The staging methods have evolved over the years and continue to play a critical role in its associated fields. When it comes to software development, staging is the environment where software is tested end-to-end before it reaches customers. It is a near-exact replica of a production environment, requiring a copy of the same configurations of hardware, servers, and databases — basically the whole nine yards — but on a smaller scale.
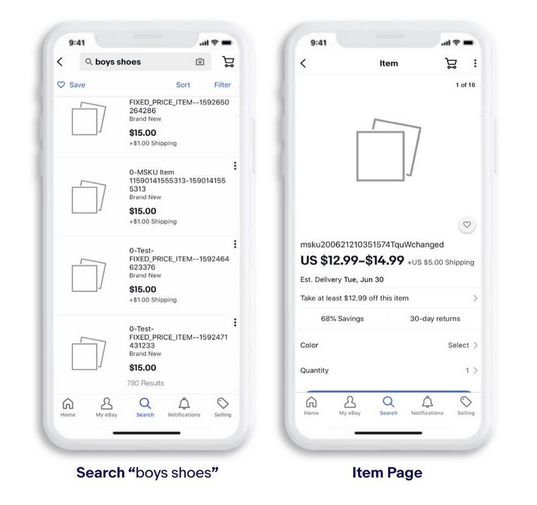
However, many organizations have been facing issues with the quality of data available in test environments in recent years. At eBay, we faced a similar challenge. Our staging data was unusable. It lacked quality and, as a result, the associated quantity. Prolonged misuse resulted in the data being futile and prosaic. Yes, there were terabytes of data, but they were not relevant for most test cases — an example below from screenshots taken in early 2020.
All organizations have a software release pipeline. The goal of a pipeline is to ensure that when the software eventually reaches production, it is thoroughly tested and ready to serve customers. A vital component of that is integration testing. We need to ensure that the system works end-to-end in all possible scenarios with zero compromises. Developers should not have any impediments in writing and running these integration test suites. To do this, we need high-quality test data. However, the constant struggle to keep them up to date has raised the question, “Do we really need to test in staging?” We explored this question in detail and tried to answer them in a two-part series titled “The Staging Dichotomy.” Coming back to the data problem, let us look into the various options available if we decide to skip staging.
Options
One option would be to create a separate zone in production that is not exposed to the public and is open only to internal eBay traffic. Developers can deploy the outgoing software in this zone and run their entire suite of integration test cases before deploying to production. We indeed have a zone in eBay like this, and it is called pre-production. The issue here, though, is that the data source behind pre-production is the same as production. This means all your test data creation and mutation happen alongside production data. When we tried this in the past, it ended up being an analytics nightmare, where the continuous runs skewed production metrics. Creating a “test” versus “customer” metrics dimension helped a little. However, the data corruption ran deep into production databases and became a real issue. Even with data teardown being part of the test suites, the massive scale of integration tests run continuously across the entire marketplace can flip the production data store into an egregious state.
Another option is to build sufficient confidence in our unit and functional testing and directly test in production with actual users.
Context Matters
Both of the above approaches have a fundamental limitation, and this is where context matters. eBay is an e-commerce platform. Transactions are essential to whatever we do. Furthermore, when there are transactions, there are payments involved. We are talking about actual items, transacting between genuine sellers and buyers with real money. The margin of error has to be minuscule. It is just not possible to execute all your test cases in production. Even if we start with a tiny amount of traffic, we need to ensure that all the dependent services work harmoniously to keep the transactions accurate. These services are also rapidly changing. The assumption that they will just work when put together in production is not worth the risk. Especially when payment is involved, even in the smallest quantities.
These conditions apply to the majority of eBay use cases. Others may not see this as a limitation. They can skip staging, directly deploy to production as a canary and ramp up traffic. The whole flow can work seamlessly. Even within eBay, few domains follow this model of bypassing staging and direct canary testing in production. However, they are restricted to read-only use cases. The rest still need staging to build confidence.
We reached consonance that a staging environment is indeed needed. But how do we fix the data problem?
Data
A common and well-established idea proposed to address data issues is to create quality data in large quantities before executing the test cases and tear them down once done. Most organizations have well-defined APIs to create data; why not leverage them? In reality, though, this is easier said than done.
Again, context matters here. It is nearly impossible at eBay to create the millions of permutations and combinations of listings required to execute thousands of test cases across the marketplace. You can create monotonous data in large quantities. However, creating a listing with multiple SKUs — with each SKU having a valid image, reserve price, 30-day return policy, and an international shipping offer with an immediate payment option — can quickly get out of hand. There is no straightforward API to create listings like this, and we need them to automate many of our Priority one (P1) use cases.
We have tried this many times in the past, and it did not work.There has to be a better way. We had to look at it from a different perspective. An idea emerged, which now, in hindsight, seems quite obvious.
“Take a subset of production data and move it to staging in a privacy-preserving way.”
eBay has 1.5 billion listings in production. Just a tiny (0.1%) subset of the listings, along with its dependency graph, should be sufficient to execute all the test cases confidently. We have to make sure that the subset is well-distributed to cover the breadth of eBay inventory. The production criteria naturally yield themselves to high-quality data. But the most important thing to us was privacy.
At eBay, we take privacy very seriously. It has been our core pillar since the very beginning. Fortunately for us, a listing and most of its associated attributes are public information. The seller and buyer’s Personal Identifiable Information (PII), along with a few item aspects like reserved price, max bid price, etc., have to be anonymized and privacy preserved. To build this pipeline, we partnered with a privacy company Tonic.ai who exactly does the same.
At a high level, our pipeline looks like this.
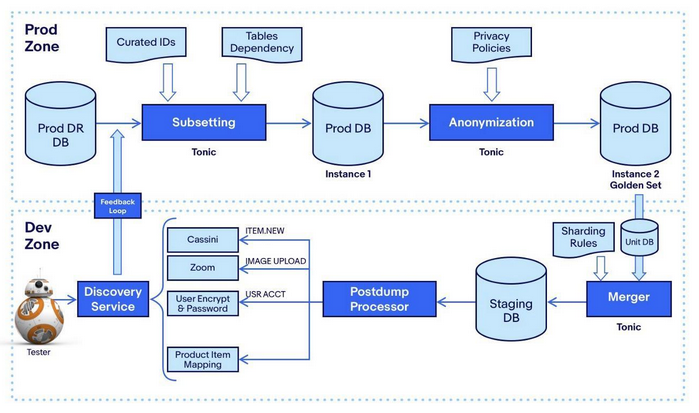
The boxes labeled “Tonic” were developed by the Tonic team. Though many boxes appear in the pipeline, only a few components are vital to the workflow.
Subsetting
At eBay, everything starts with a listing. The goal of subsetting is two fold — identify the listing IDs that are required to execute all our test cases and plot a course to fetch all the required and auxiliary information associated with those listings. To begin with, we took one domain (item page) and extracted all the regression test cases necessary to certify a release to production confidently. It included even the rare and complex data scenarios. From those test cases, we formulated a set of SQL queries that ran against our Hadoop clusters. The queries included listings from all sites and across all categories based on hundreds of item and user flags. The final output is a list of unique listing IDs that specifically target the domain test cases.
The above-extracted item IDs are fed as input to the subsetter. The job of the subsetter is to plot a course, starting with the main item table. To do that, we topologically arrange the tables to map their dependencies. Next, using the curated IDs as queries, the algorithm goes upstream of the target table to fetch the optional auxiliary data (e.g., bids of an item. It is optional because an item can exist with no bids), followed by going downstream to fetch all required data (these are mandatory, e.g., bids must have an item). Once all downstream requirements are satisfied, the subsetting is complete. We call this referential integrity.
Anonymization
Once a set of production tables is identified from which data will be copied, the workflow alerts our information security and privacy teams, and the pipeline is halted. It is a deliberate step to ensure that none of the data leaves the production zone without the review and approval of our security and compliance systems. It only happens when a new table is recognized or an existing table is modified. So our daily runs (explanation comes below), configured only with previously approved tables, are mostly uninterrupted. There are a set of PII-related columns within a table that are by default flagged to be anonymized.
The first step for our information security team is to go over them and flag more columns as appropriate. They have their own set of criteria based on international compliance rules and policies, which by just looking at the data may not seem obvious. This process flagged approximately 27% of our columns.
The second step is to take a sample of anonymized data and verify if the standards are met. The information security team’s process is a mix of both automation and manual verification. Since the process is triggered only for new tables, it was not a hindrance. Establishing this tight feedback loop and stopping when in doubt setup helped us ensure that privacy is always preserved.
The technical novelty of the anonymization is important to highlight. We cannot apply some random encryption to anonymize the data. We need Format-Preserving Encryption (FPE), where data in one domain maps to the same domain after encryption, and it should not be reversible (e.g., encrypting a 16-digit credit card number yields another 16-digit number). In eBay’s context, this becomes very critical; or else, most test cases would fail. Using Feistel network and cycle walking, we can create a bijection between any domain and itself, e.g. the domain of 16 digit credit card numbers.
Merging and Post Processing
The anonymized data moves from the production zone to the staging zone adhering to all our firewall protocols. Now comes the merger, whose primary responsibility is to insert the subsetted anonymized production data into the corresponding staging tables. In actual implementation, there is much more nuance to it. For instance, remapping previously migrated sellers to their new items is a complex and costly endeavor. A good side effect of the merger is that it helps identify schema differences between staging and production tables, which did exist due to prolonged staging misuse.
The pipeline does not stop at the merger. There is one more important step, which we call the “Postdump Processor.” Once the data is inserted into the staging tables, this component fires a series of events. The goal is to orchestrate a sequence of jobs to penetrate and normalize the newly migrated data throughout the staging ecosystem. The Postdump Processor includes tasks like notifying the search engine to index the new listings; mapping items to existing products; uploading listing images to staging servers and updating endpoints; using staging salt to hash user credentials; and a few more. We piggybacked most of the existing async events triggered when an item is listed on eBay. A few new ones were created just for the pipeline use cases. This post-processing step is what makes the data relevant.
Discovery and Feedback Loop
Now that high-quality data was made available in staging, a way to exclusively query them for all automation needs became paramount. We have existing APIs to fetch items, users, orders, transactions, etc. However, all of them were built with a customer and business intent in mind and not how developers or quality engineers would use them in their automation scripts. Just like the difficulties of using existing APIs for data creation, there is no straightforward way, for instance, to fetch a bunch of items that have more than 10 SKUs and 40 images. It becomes an arduous process. To solve this, we created a Discovery API and UI tool (codenamed Serendipity), which makes it seamless to integrate with all automation scripts. The API only queries the migrated data that are watermarked with a special flag during migration. The filters in the API are targeted toward how engineers write test cases without worrying about entity relationships or microservice decoupling.
The final aspect of the pipeline is to create a healthy feedback loop between its two ends — production ID curation and staging discovery. The way we achieved it is by adding observability to the discovery API. When a fetch returns null or low results, it immediately signals the dataset curation system to migrate those items in the following pipeline run by executing the corresponding production SQLs. Similarly, when new product requirements come in, developers can request those filters in discovery, which translates to SQLs on the curation side. A self-serving pipeline, indeed.
Expansion
What started as a proof of concept with one domain, 11 tables, and a few thousand items has expanded to the whole marketplace. Today, we have over a million high-quality listings in staging, along with its associated upstream/downstream dependencies. They serve the automation needs of a majority of our applications. Every day, 25,000items/orders are migrated from production to staging, and the data is spread across 200+ tables, 7,000 categories, and 20 different DB hosts. Beginning this year, we expanded the pipeline to NoSQL databases. This includes MongoDB, Cassandra, Couchbase and eBay’s open-sourced NoSQL offering Nudata. The pipeline architecture is the same for NoSQL, with the curated listing IDs used as keys for subsetting.
The pipelines themselves are parallelized at a macro-level — multiple pipelines running on dedicated machines, creating redundancy on failures, and at a micro-level — each component is multi-threaded when possible to execute faster. The pipeline runs every four hours and, on average, takes 65 minutes end-to-end. We have dedicated pipelines for migrating new tables, so it does not impact daily runs. Purging happens on item expiry, similar to production. There are also daily purge jobs to clean up the auxiliary data.
Not all test cases will be covered by data migration. There are use cases for which data creation is required. They are transient data primarily associated with users. Migrating data for these scenarios will be an unnecessary overhead. For this, we have created a new tool called the data creation platform, which again seamlessly integrates with automation scripts.
Virtuous Cycle
The presence of high-quality test data enabled us to create a virtuous flywheel. Now that application teams were empowered with good data, we set a high staging availability goal for them to maintain. This created a cycle that is continuously improving.
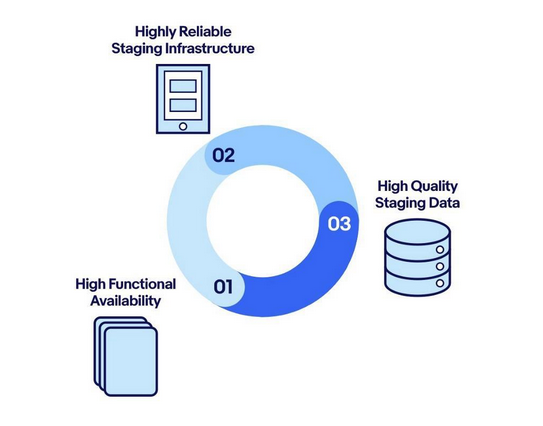
As outlined in the diagram above, the three building blocks of the staging flywheel keep each other in check and strive for improvement. The high staging availability goal becomes a motivation to keep staging infra reliable and stable. Subsequently, for infra to be fully useful, it requires quality data. Which again becomes a motivation for the data pipeline to be on top of it. And with high-quality data, functional availability is even further improved. The cycle continues.
Wrapping Up
Today, 90% of all automated integration testing happens on staging. The pass rate is at 95%, compared to only 70% in 2020. Flaky tests are a big frustration point in software development. Even a minor improvement can have a multiplier effect, and we saw that with the jump in the pass rate. Also, in the past, teams pushed code to production with less confidence and executed a considerable number of sanity tests directly in production to validate functionality. Now that reluctance is gone. Only around 5% sanity testing happens on production, with the rest becoming integration tests executed on staging. Speaking about release velocity, we reduced our native app (iOS and Android) release cycles from three weeks to one week, and staging was a key enabler in achieving that.
It has been more than a year’s journey to get to where we are today. More than that, it has opened endless possibilities, and that is what keeps us excited. The staging data team’s commitment is to keep evolving the virtuous cycle and, in that process, find more opportunities to improve developer productivity.
We now believe that we have found a stable solution to the test data problem, and the impact has been profound.
About the Author

Senthil Padmanabhan is a Vice President, Technical Fellow at eBay, where he heads the user experience and developer productivity engineering across eBay’s marketplace. Since joining eBay, Senthil has led several critical initiatives that were transformational to eBay’s technology platform. He is the creator and implementer of many libraries, UI systems, and frameworks used throughout the eBay code base. His leadership has paved the way for rapid software development and innovation across the organization, and he was recognized as one of the 2018 honorees for Silicon Valley Business Journal’s 40 under 40.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind