Barbara Murphy, VP of Marketing, WekaIO, explores how as as AI production models grow larger and more intricate, server architecture can get more and more complex. Explore how tools like GPUs and more are moving the dial on AI.
The use of machine learning (ML) to derive insights, automate repetitive tasks or to enhance human decision making has reached exponential growth levels. The technology is being utilized broadly to detect fraud, automate driving tasks, scan medical images, predict manufacturing failures, enhance financial trading strategies, and many more.

Barbara Murphy, VP of Marketing, WekaIO
While ML is still considered a relatively nascent technology, across industries it is a race to be the first across the line, whether the first to showcase a fully autonomous vehicle or successfully develop automated healthcare systems. Time to market is measured in how fast machine learning models can be trained, and how big the data set that is driving the training model. Put simply this is a balance of two key factors, data and compute. More data equates to more accurate models and more compute equates to faster training.
It is not uncommon for model development to start out with a simple infrastructure model, a single GPU server with a single view to the data set. In this case, the data set is often small enough to fit in the locally attached storage inside the GPU server providing great performance and fast completion of an epoch (the time it takes to run a single machine learning model training run).
Figure 1: Simplified data flow from storage to GPU server (Graphic: WekaIO)
As AI production models grow larger and more complex, it requires a server architecture that looks much like high performance computing (HPC), with workloads scaled across many servers and distributed processing across the server infrastructure. Figure 2 provides an outline of a clustered GPU server environment, in this distributed environment the data flow becomes significantly more complex, with many different servers requiring access to the same data set at the same time, and the actual flow of data could be mixed between multiple servers. However, it is critical that a single view of the data set is preserved across the clustered server infrastructure.
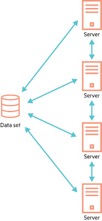
Figure 2. Deep learning model, single data set serving multiple GPU servers. (Graphic: WekaIO)
The Challenge of Scale
For complex tasks like autonomous driving, it is not uncommon for data sets to grow to tens or hundreds of petabytes for a model. With data sets this large, it requires a storage system that can serve up a single view of the data to all servers in the cluster, but the sheer size of the data set precludes the use of locally attached storage. The architecture has to rely on networked storage to deliver the scale of data required to train the models.
Scaling a large data set to single machine is relatively straightforward, the challenge is how to deliver comparable performance to a complex data flow described in figure 2. All servers need to ingest data from a single source, placing immense pressure on the shared storage system. In the real world, performance generally deteriorates as the workload scales largely due to the bottleneck created from the data preprocessing and network latencies.
Infrastructure choices have a significant impact on the performance and scalability of a DL workflow. Model complexity, catalog data size, and input type (such as images and text) will impact key elements of a solution, including the number of GPUs, servers, network interconnects, and storage type (local disk or shared). The more complex the environment, the greater the need to balance components. HPE has integrated best-in-class components into its server infrastructure for DL, including GPUs from NVIDIA, 100 Gbps InfiniBand networking from Mellanox, and the Matrix high-performance shared file system software from WekaIO.
Benchmarking Performance at Scale
HPE set out to investigate the storage impact of scaling data training from a single GPU server to a clustered multi-node environment utilizing WekaIO Matrix shared file system. The purpose of the benchmark was to measure the impact (performance degradation) the external shared storage system would have when scaled from a single GPU server to a multi-node environment.
The team leveraged the HPE Apollo 6500 Gen10 GPU servers, each with 8 NVIDIA Tesla V100 SXM2 16GB GPUs per server. The performance benchmark scaled from a single Apollo 6500 GPU server to four, for a total of 32 GPU complex.
The external storage system leveraged the HPE ProLiant DL360 servers, interconnected with Mellanox 100Gbps EDR networking, running WekaIO Matrix flash-optimized software. Independent I/O benchmarks had previously verified that this storage solution is capable of delivering over 30GBytes/second of sequential 1MB reads and over 2.5 million IOPS for small 4K random reads. The infrastructure is capable of scaling to hundreds of storage nodes and tens of petabytes in a single namespace, more than sufficient to handle the even the largest DL training data sets.
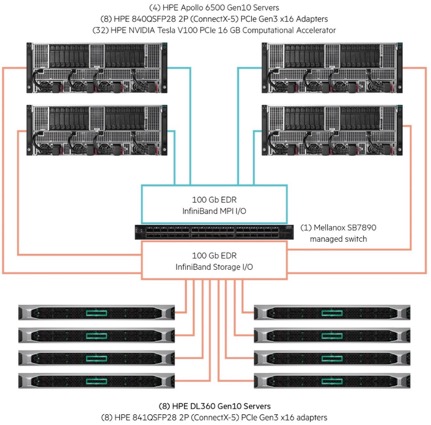
Figure 3. Deep Learning benchmark environment leveraging HPE reference architecture
The performance tests were conducted using the popular ImageNet data set stored in a standard Record format across a variety of popular benchmarks. The complete list is outlined in table 1, along with the batch size used. The same batch sizes were used for both training and inference.
| Benchmark | ResNet152 | ResNet50 | Google Net | VGG16 | Inception-V4 |
| Batch Size | 128 | 256 | 128 | 128 | 128 |
Table 1. Training benchmarks conducted and batch size used.
The training data results, outlined in figure 4, clearly show that HPE Apollo 6500 Systems with varying quantities of NVIDIA SXM2 16 GB Tesla V100 GPUs scale near-linear performance across a variety of benchmark tests. The testing results show that using one server with eight GPUs delivers comparable performance to using two servers with four GPUs each, or four servers with two GPUs each. In other words, the storage system can easily handle a scale-out as well as a scale-up deployment.
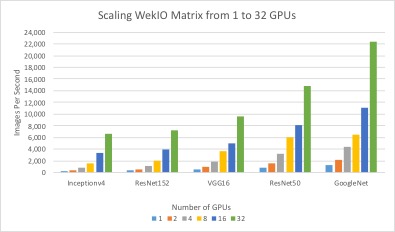
Figure 4. Scaling performance from a single GPU to 32 GPUs, across 4 Apollo 6500 Systems
Worth noting is the ease of use of a configuration leveraging WekaIO Matrix. Due to the removed dependence on data locality, it is very easy to add new Apollo 6500 Systems to a test environment using a shared filesystem architecture. No additional data copying is needed to prepare additional clients, which helps to create an agile and flexible architecture for such a rapidly growing use case. As compute requirements increase, WekaIO Matrix and Mellanox networking provide excellent performance and ease of scaling.
For full details on the testing completed by HPE, see here, and download the complete white paper.
Get the first whitepaper in this series from HPE, WekaIO, NVIDIA and Mellanox at Time to Value and AI Insights.
Get more information on WekaIO at www.weka.io, or find out more details on the solutions from HPE and WekaIO here.



Speak Your Mind