
A unique convergence of three mega trends helped bring Artificial Intelligence out of academia and made it ubiquitous in everyday applications – big data, cloud compute, and advanced algorithms. Today, AI has fundamentally changed how software is written and it is integrated into daily digital experiences, such as writing emails, searching the web, buying clothing, searching and listening to music, and building websites. Somewhat slower, though, has been the spread of AI in the global infrastructure systems of manufacturing, transportation, aviation, power generation, financial services, and other industries.
While these industries have large amounts of data, the data is often:
- not in the public domain; e.g. oil exploration or environmental impact reports in oil and gas
- requires highly knowledgeable humans to annotate; e.g. sensor data from gas turbines, pumps, compressors
- is held in complex data stores, in many formats, and not always cleansed; e.g. aircraft maintenance logs or manuals
These very real challenges make applying the same AI techniques that revolutionized internet search, reading invoices, translating languages, and holding conversations inapplicable as-is to specialized domains.
Practitioners of AI in industry are realizing that conventional supervised machine learning approaches and large scale models from academia and research often fail in specialized domains, making the operationalization of big data in the commercial enterprises very difficult. As Chirag Dekate, Senior Director Analyst, Gartner said in 2019, “launching pilots is deceptively easy but deploying them into production is notoriously challenging.”
Rather than relying on data scientists and software developers, the key to industry adoption is to empower Subject Matter Experts (SMEs) who intimately understand processes and data. However, enabling SMEs, like aircraft technicians, power plant operators, financial analysts, customs agents, and others to define, build, and deploy their own purpose-built AI intuitively and rapidly requires new approaches to data discovery, tooling, automation, and validation of data science.
Some of the proven techniques to operationalize the most prevalent forms of Big Data in enterprises include:
Creating Early Warnings for Unplanned Asset Downtime with Normal Behavior Modeling on Digital Sensor Data
Industrial operations often depend on critical high-value assets like gas turbines. A single day of unplanned downtime or outage can cost a power company or utility provider ~300K in lost revenue–the disruption to consumers can be significantly more severe. Due to their critical nature, these systems are typically overbuilt with redundancy and have comprehensive preventative maintenance programs. Ironically, this makes traditional supervised machine learning difficult as there are very few failures during the system’s life.
Normal Behavior Modeling is a domain agnostic, semi-supervised machine learning technique that can be used to rapidly model any system by representing it as a combination of process parameters. SMEs identify timeframes of normal behavior of the system in historical data and then AI starts to learn the latent relationships between the process parameters. Autoencoders are a type of neural network that train on the historical data and store the latent relationships as a set of weights. Once the autoencoder is trained, it can be used to predict or regenerate the input process parameters. If and when the predicted or regenerated values of the process parameters do not match the measured, historical values, the normalized error is used as a measure of “abnormality” or anomaly.
Before this type of Normal Behavior model can be productized, it needs to be back-tested against a historical record of actual outages and events in the system. If the selected process parameters represent the behavior of the system well, then preceding any outage, some or all the parameters should start trending into an abnormal range. The Normal Behavior model should predict this by raising the level of abnormality. If the abnormality level is raised enough in advance of an outage consistently, it can be used to create an early warning system for outages in the future.
In practice, tens or hundreds of normal behavior models can be automatically trained using hyper-parameter optimization. An objective function is created to measure both the accuracy of the predictions and the length of the early warning. This objective function makes it possible to programmatically evaluate and rank all model variants and deploy the best ones into production. Additional layers of tuning can be added to select the right dynamic thresholds for emitting alerts based on the abnormality level and the preference of the user.
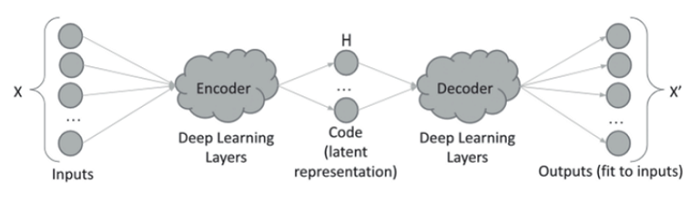
Normal behavior model offers the following advantages over traditional modeling:
- Domain agnostic. The approach can be used as long as process variables are measured/recorded with reasonable frequency and precision.
- Unsupervised learning. Upfront effort is limited to variable selection and identifying nominal operating conditions and can be typically performed by SMEs.
Finding Patterns in Natural Language Records using Ad-hoc Density-Based Clustering
Natural language records are very commonplace in industrial environments forming the basis of a wide range of processes like product test, application/security logs, equipment maintenance, logistics, shipping, and more. In practice, most records in enterprises are semi-structured records, with one or more columns of structured data (numbers, dates, categories) and one or more columns or natural language text that are usually created for human consumption. The need for semi-structured records is almost emergent in enterprises. In an ideal world, all data collected about a process could be numbers, dates, and multiple choice categorical elements. However, in practice, there are multiple reasons that natural language gets introduced into records:
- Not all process modalities are known at design time, leading to “other” or catch all categories.
- Instructions or procedures are best represented as natural language and are constantly improved over time.
- Troubleshooting, diagnostics, investigations, and more usually generate knowledge that previously unknown making natural language necessary.

Operational records in enterprises are often functional/terse, contain typos and colloquialisms, and generally contain acronyms and jargon (e.g. ty-wrap = Tyvek wrap, ee = employee). This makes standard search and natural language modeling techniques somewhat ineffective. Additionally, there can be a myriad of ways to use the natural language so a comprehensive scheme for normalization is untenable. Eg. the incident above can be categorized by its severity (i.e. minor injury) or it could be categorized by point of injury (i.e. hand injury). The two categories are not mutually exclusive and need to be thought of as separate categorization schemes. Without high effort from SMEs, most natural language records are rarely analyzed and remain unutilized.
A practical approach for finding useful patterns in natural language records is ad-hoc clustering. To retrieve information, SMEs first use common search techniques on their records. However, reading through results in the hundreds is often tedious and simply consuming top “n” results leaves room for missed information. To avoid these pitfalls, the AI applies density-based clustering on the search results. When density based approaches like DBSCAN or HDBSCAN are used on sentence embeddings of records, they tend to cluster semantically similar language without being highly sensitive to spellings, conjugations, typos, and colloquialisms. SMEs can easily read a couple of representative records in a cluster to fully understand it. Additionally, analysis of the top “n” clusters typically exposes all predominant patterns of information in the search results. These clusters can now also become initial candidates for a classification scheme which can create categorical structures around the data progressively. This technique constantly demonstrates high value in long-tail search problems when the SMEs intents cannot be accurately and completely known in advance but can be defined and applied over time.
Retrieving Information or Knowledge from Documents using Discovery Loops
In order to drive critical and time-sensitive decisions, analysts in every industry vertical, government agency, and military branch are met with massive fire hoses of content that have to be processed. Executives count on analysts to accurately interpret reports, news, advisories, and investigations to provide decision support for confident, well-considered decisions. Searching for the right content through exploratory reading is cognitively taxing and creates decision fatigue. Moreover, analysts are typically exploring esoteric concepts that are hard to clearly articulate using keywords and logical rules required by standard search tools. Analysts generally agree that, “they know it when they see it.”

In considering the narrative text example from the above news excerpts:
The second example actually does not use the word “outbreak” but an SME might quickly assess it as a leading indicator of an outbreak. To address these esoteric knowledge capture scenarios, SMEs first search their documents with one of more keywords representing the ideas they want to find. The Discovery Loop AI then selects 25-50 most representative sentences from the results and with simple point and click gestures, enables the SME to bucket the results into one or more meaningful categories. Alternatively, the SME can also indicate sub-strings from the sentences to extract as verbatim. The AI trains a CNN classifier to learn the categories assigned by the SME. Any sentences left unbucketed are automatically assigned to a “not interesting” category. The model thus trained runs inference against all sentences in the original search results. Based on the inferred category predictions and their relative prediction confidence, the AI presents at least 2 groups of sentences for the SME to review and/or correct – “most like label x” and “least like label x” based on the category labels assigned to the initial group of 25-50 sentences. Since the AI only trains models on 25-50 sentences and runs inference on the search results, the loop usually takes only minutes. Similarly, each review group is only 25-50 sentences each, requiring only minutes of review by the SME. This rapid iteration is known as the Discovery Loop and enables the SME to quickly discover information without focusing on keywords but rather merely reading and making point decisions. As the SME curates more labeled sentences, the AI retrains the classification or extraction model to improve accuracy and increases coverage of the document set by performing query expansion using keywords extracted from labeled sentences. At any time, the model can be run against all sentences in the document set to get a comprehensive subset of sentences matching the esoteric concept defined by the SME, which can then be cited or referenced as evidence in the Analyst’s report.
Both the ad-hoc density-based clustering and Discovery Loop offer the following advantages over classical supervised classification approaches:
- Reduce tedious, comprehensive labeling burden required upfront for classical approaches
- Enable SMEs to develop categories progressively as they discover new information
- Enable SMEs to only model a useful subset of the data
A common feature of all the techniques is using augmenting SME knowledge and intuition with AI which enables them to focus on high-value decisions. By eschewing classical supervised modeling approaches popular in academia, these techniques focus on rapid utility by providing just-in-time intelligence at the SME’s fingertips.
About the Author

Jaidev Amrite, Head of Product for Visual AI Advisor and DeepNLP, SparkCognition. Before SparkCognition, Amrite led multiple product development initiatives in IIoT, Data Analytics and Embedded Systems at National Instruments and Microsoft. He earned his Masters in Electrical and Computer Engineering from Georgia Tech and is passionate about making technology approachable through human centered design and social psychology.
Sign up for the free insideBIGDATA newsletter.
Join us on Twitter: @InsideBigData1 – https://twitter.com/InsideBigData1



Speak Your Mind